Accelerating 3D Gaussian Splatting
Research-focused performance optimizations for the CUDA rasterization backend used in 3D Gaussian Splatting training.

3D Gaussian Splatting (Kerbl et al. 2023) enables high quality real-time novel view synthesis, but training remains performance sensitive due to heavy forward and backward rasterization passes.
It is a derivative work of graphdeco-inria/diff-gaussian-rasterization, extended to study memory behavior, kernel efficiency, and training throughput under visual quality constraints.
This project profiles and accelerates the CUDA kernels by targeting:
- Redundant global memory traffic
- Cache behavior (L1/TEX vs shared memory)
- Atomic operation pressure in backward passes
- Bandwidth-dominated workloads
Optimizations
1. Image Chunk Size Allocation Fix
Corrected buffer allocation by separating per-pixel buffers from per-tile buffers. This reduced temporary image chunk memory from 16.0 MB → 8.4 MB, improving memory correctness without changing runtime behavior.
2. Shared-Memory Caching
Extended the cooperative fetch stage to cache per-Gaussian feature vectors and depth values. This eliminated redundant per-thread global loads inside the innermost compositing loop.
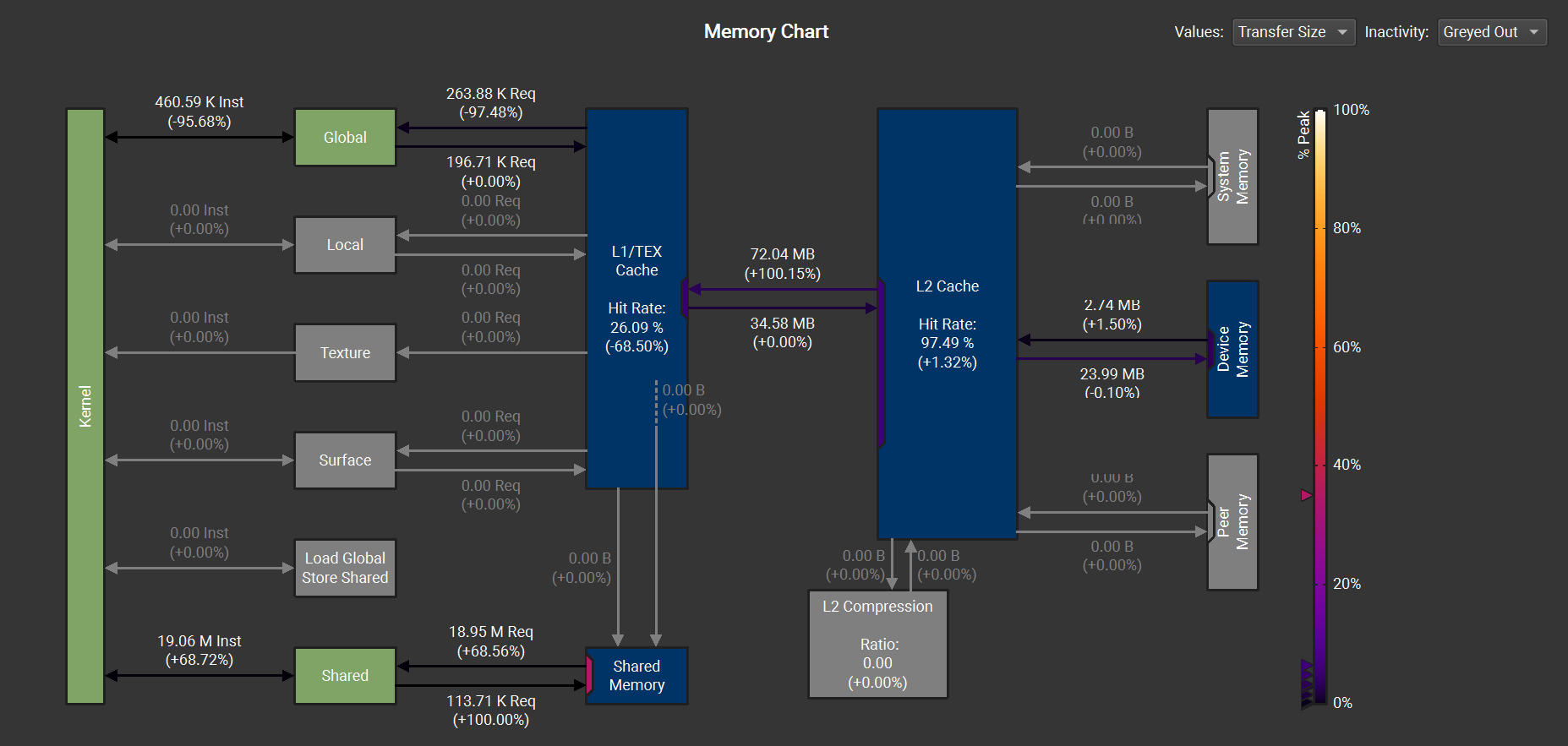
- -95.7% global memory instructions
- -68.5% L1/TEX activity
- +68.7% Shared-memory loads
- Kernel time reduced 2.85 ms → 2.50 ms
This shifts reuse from implicit cache behavior to explicit shared-memory reuse, yielding more predictable access patterns and slightly higher SM utilization.
Note: In higher iterations, both memory accesses have similar runtime.
3. Atomic Operation Reduction (Experimental)
Targets the backward rasterization kernel by staging partial results in shared memory to reduce repeated atomic updates.
Achieved 2.88× faster training (190s → 66s), though with some visual quality degradation due to numerical interference.


4. Mixed-Precision Spherical Harmonics
Stores SH coefficients in FP16 to reduce bandwidth/VRAM usage, converting to FP32 in registers for arithmetic.
- +45.6% training throughput
- -18% peak VRAM usage



Validation & Metrics
All optimizations are evaluated under identical training settings and validated using profiling tools.
- Image Quality: NVIDIA FLIP
- Profiling: NVIDIA Nsight Systems, Nsight Compute
- Metrics: Iteration time, Throughput (it/s), Memory Traffic
- Datasets: Playroom (baseline) & Truck (high-load)